Hamza Salah

Data Science (M.S. graduate), passionate about building ML and forecasting solutions across diverse domains.
![]()
![]()
![]()
![]()
Return Prediction in E-commerce
Project Overview
This academic project focused on modeling and predicting product returns in e-commerce, a problem estimated to cost the retail sector nearly $890 billion annually. Using a simulated dataset with intentional biases, the goal was to identify key risk factors and build an interpretable binary classification model to predict the target variable, is_returned. The analysis utilized a Logistic Regression model trained with balanced class weights to enable proactive business intervention and reduce costs associated with returns.
Key Insights
-
Dominant Predictors: The strongest predictive features identified were the Cash payment method and weekend orders (Friday, Saturday, Sunday). These non-logistical factors significantly outweighed product-level factors in predicting returns.
-
Target Performance (Recall): The model achieved a valuable Recall (Sensitivity) of 60% for the minority class (Returns). This high recall allows the business to correctly identify three out of every five potential returns for pre-delivery intervention.
-
Model Trade-off: The model suffered from low Precision (0.24) and a weak F1-score of 0.34 for the Returns class, indicating a high rate of False Positives. Overall model Accuracy was 62%, and the Area Under the Curve (AUC) score was 0.70.
-
Data Handling: The dataset contained 100k records and exhibited a severe class imbalance, with only 16% of records indicating a return. The use of balanced class weights was critical for training, but the primary success metric was Recall.
Key Visualizations
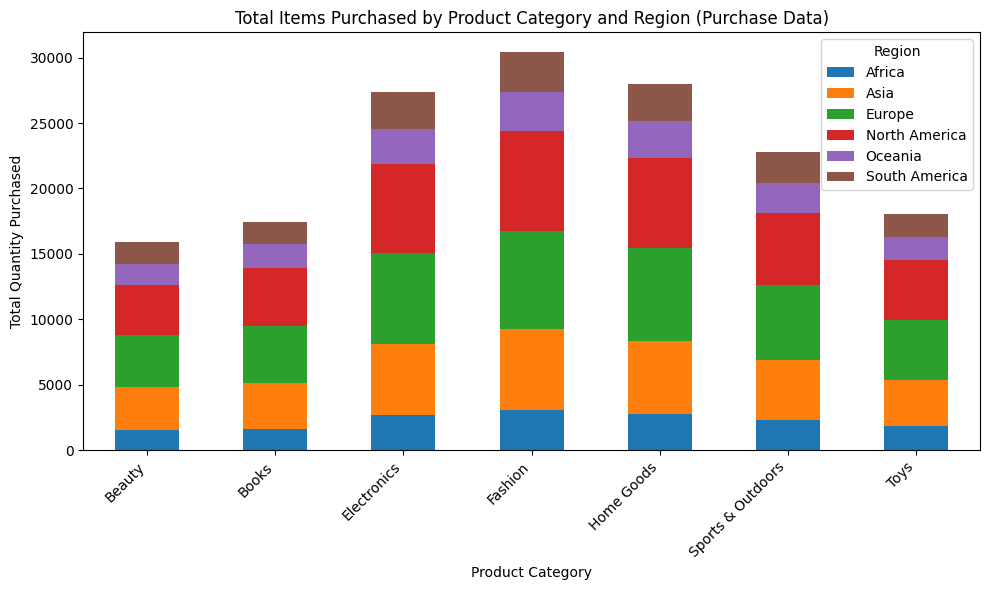
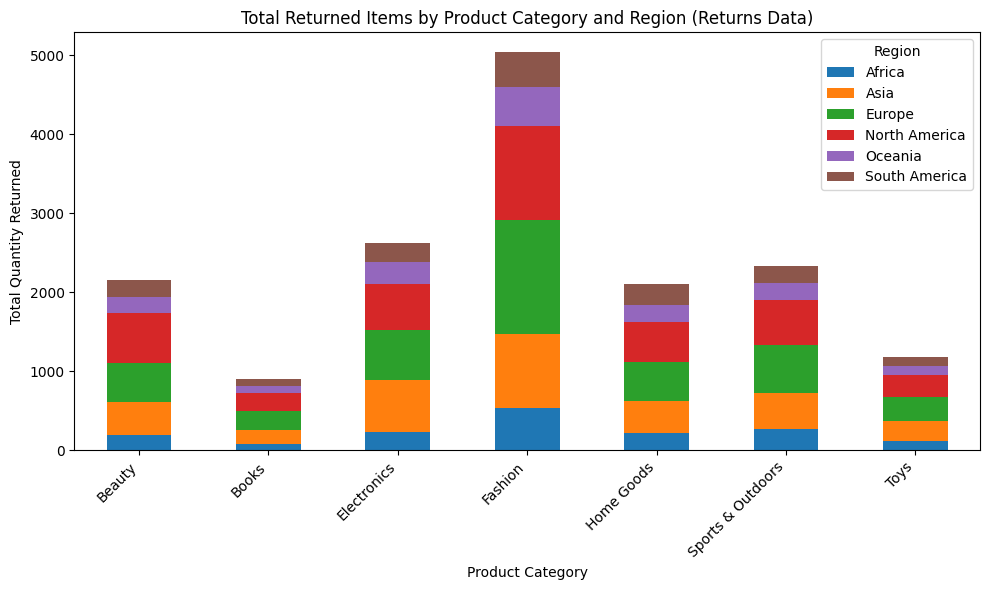
Business Recommendations
- Prioritize Interventions: Focus intervention efforts primarily on orders made using the Cash payment method and those placed on weekends. Interventions could include immediate pre-shipment quality checks or targeted confirmation communications.
- Optimize Decision Threshold: To strategically reduce the cost associated with False Positives, raise the classification decision threshold from the default 0.5 to 0.7 or 0.8. This increases the confidence (Precision) of flagged orders at the expense of Recall.
- Future Work: Future modeling efforts should focus on implementing more advanced classifiers (e.g., Gradient Boosting) and engineering features related to customer history (e.g., past return rate).
Code and Data
Technologies Used
- Python (Pandas, NumPy)
- Scikit-learn (Logistic Regression, evaluation metrics)
- Jupyter Notebook
- Matplotlib, Seaborn